




Previous: 1. Database description:
Up: 8. Polyhedral Databases
Next: 3. Incoherent Databases:
We have decided to use two different databases to study the effect of
different databases: one is biased, i.e. towards large size polyhedra,
and the other is periodically sampled since it contains many
polyhedra. We have considered two types of POLYBENCH databases, for
each operator. For instance, with the satisfiability test in
6_tab:satisfiability_databases:
- Sampled Database: constraint systems are periodically
selected with probability at intervals of
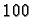 , i.e., for every
hundred constraint systems, we take only one, which means we use only
, i.e., for every
hundred constraint systems, we take only one, which means we use only
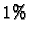 to speed-up experiments and obtain average results. We have
chosen for the sampling adapting to our experimentation:
is still quite large for satisfiability databases that relatively
assures accurate measurements. And even with only , the execution
of the satisfiability test databases still last a week: while the
input/output, database compression/decompression, computations of
polyhedral characteristics, e.g. number of vertices, for each input
using the Chernikova algorithm, output comparisons and timeout
exception cases, which are not counted in our displayed total
execution time as explained in 6_polybench_implementation,
already require important execution times, our implementation of
head-to-head comparisons sometimes requires several executions of the
same implementation on the same databases, which adds up to the total
execution times. For example, JANUS versus Simplex and JANUS versus
Fourier-Motzkin need two executions of JANUS on our satisfiability
databases
to speed-up experiments and obtain average results. We have
chosen for the sampling adapting to our experimentation:
is still quite large for satisfiability databases that relatively
assures accurate measurements. And even with only , the execution
of the satisfiability test databases still last a week: while the
input/output, database compression/decompression, computations of
polyhedral characteristics, e.g. number of vertices, for each input
using the Chernikova algorithm, output comparisons and timeout
exception cases, which are not counted in our displayed total
execution time as explained in 6_polybench_implementation,
already require important execution times, our implementation of
head-to-head comparisons sometimes requires several executions of the
same implementation on the same databases, which adds up to the total
execution times. For example, JANUS versus Simplex and JANUS versus
Fourier-Motzkin need two executions of JANUS on our satisfiability
databases![[*]](http://www.cri.ensmp.fr/latex2html/foot_motif.png) . Since other
databases are smaller, we use no sampling when possible;
. Since other
databases are smaller, we use no sampling when possible;
- Filtered Database: only large size constraint
systems, large according to some size criteria, are selected to
analyze better the impact of exceptions. Thus this database is biased
on purpose. We have used the following criterion:
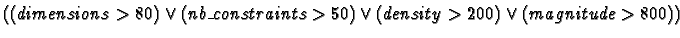 . It presents the case where the ``size'' of
constraint systems is relatively large, which might lead to large run
times according to our experimentation on some extracted examples. We
notice here that, for some cases, these databases are very small or
even empty, thus they are only used for statistical purposes.
. It presents the case where the ``size'' of
constraint systems is relatively large, which might lead to large run
times according to our experimentation on some extracted examples. We
notice here that, for some cases, these databases are very small or
even empty, thus they are only used for statistical purposes.
Previous: 1. Database description:
Up: 8. Polyhedral Databases
Next: 3. Incoherent Databases:
Nguyen Que Duong
2006-09-16